



by Kayle Simpson, on June 21, 2016
If you do a quick Google search for "what is a data lake" you'll likely find this result from TechTarget:

While this definition does address this, my initial thought when reading this was "wait.. so it's a fancy data warehouse?" - and I'm not alone on this. Data warehouses and data lakes are compared all the time, and while they're both data storage repositories, they serve very different purposes and are useful in different ways. While there are a lot of technical differences between data warehouses and data lakes, which we will get into, the primary difference is who they're most useful to.
So let's take a look at those technical differences:
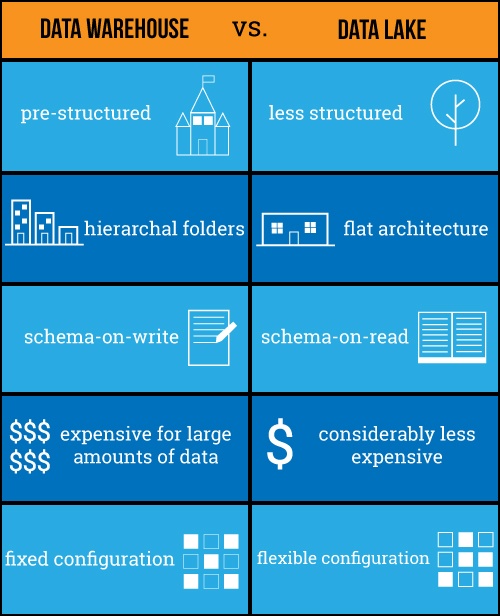
Yes, data warehouses are structured, hierarchal, with few moving parts, and data lakes are flexible, raw data repositories, with a flat architecture. But what does that really mean?
Data warehouses are primarily built for business analysis. The end user isn't always a data analyst or a developer, and because of that, more of their structure and architecture is predetermined so that everything is neat and organized enough that anyone can make use of the data.
On the other hand, data lakes are built for data people. They're fast, flexible, and filled with raw data that is ready to be manipulated. Data scientists and developers can experiment in data lakes and find insights that wouldn't have been possible in a data warehouse, but without the risk of messing up its usability for everyone else. Data lakes can save a lot of time and money, but only if your company has a team that knows what they're doing.
Hopefully now you have a better understanding of what a data lake is, what it's useful for, how it can be useful to you, and the differences it has compared to a data warehouse.